Many organizations and engineers are considering adding the powers of machine learning and artificial intelligence to their toolbox. Often organizations do not have direct access to machine learning experts. In this article, we outline the top success factors for machine learning projects.
Must-Have Real Need for ML
In the hunt for competitive advantage, some organizations reach for the latest technologies, including machine learning. Machine learning is not the right technology for every engineering problem, say machine learning experts. In fact, whenever a more straightforward algorithmic solution exists, it is preferred.
In machine learning, as the name implies, computers must learn to recognize patterns and solve problems similar to the way humans do. While this opens the possibilities for innovative solutions, it also introduces the possibility of errors. Similar to humans, machine learning algorithms make mistakes. Depending on the problem domain the error rate can be significant.
How does one know if machine learning is the right tool for the job? The best way is to engage machine learning experts.
Algorithmic Innovation Alone is Not Enough
If it is determined that machine learning is in fact the right tool for the job, it is not enough To invent new machine learning algorithms to gain a competitive advantage. Intuitively it may seem that inventing new machine learning algorithms would impart certain advantages, however, machine learning practitioners are very good at reverse engineering new algorithms. Machine learning is in a mature state where new innovation is very often only an incremental modification to an existing algorithm.
The reality is that machine learning algorithms are quickly commoditized and open-sourced, and many practitioners work on similar problems thereby inventing similar algorithms. In addition, the machine learning community is tightly knit and information tends to flow freely.
It’s All in the Data
Turns out, it is actually proprietary data that is difficult to procure. Why would one need proprietary data? If a problem is solved using freely available data, a company cannot hope to gain a competitive advantage, as the same data is available to all of its competitors. Therefore, a competitive advantage can only be obtained by starting with a data set that no competitor has access to.
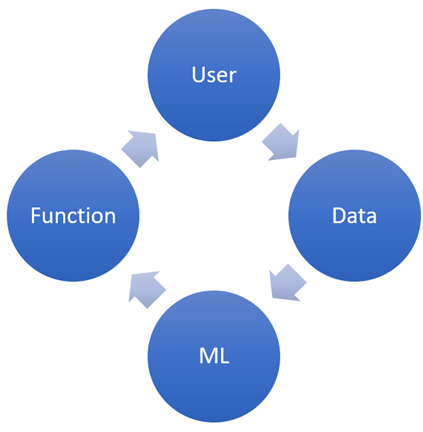
It is best to try to create a data flywheel, which is a virtuous cycle that, once in production, generates more proprietary data, as shown in the figure below.
Machine Learning and Domain Experts are a Must
Machine learning is hard. Using algorithms is not what is hard about machine learning, but learning all of the ways in which data manipulation can yield unreliable results. Unfortunately, the results do not come with labels that let a researcher know if the results are meaningful or junk. It takes many years of practice and making mistakes to learn all the different ways that a machine learning algorithm can produce unreliable results.
at the same time, it is also important that a machine learning expert is paired up with a domain expert. Too often a machine learning expert is asked to become a domain expert in a problem overnight, which is unrealistic. Just as unrealistic as asking a domain expert who wields machine learning tools like an expert overnight. It’s best to deploy both types of experts.
Machine Learning Experts to the Rescue
At Sidespin Group we have seen our fair share of machine learning projects that have gone astray for the lack of proper expertise on board. We are here to help with machine learning expertise and can advise on how best to go about a project to ensure success. For help with AI/ML strategy please contact Sidespin Group’s machine learning experts for guidance.